
In this post, we will explore the following:
- What is open core?
- How is it implemented?
- Where are examples?
- When should it be used?
Data overwhelmingly shows that open core (OC) is the dominant business model used by the most successful COSS companies.
OC is the most misunderstood and polarizing business model implemented by COSS companies.
Misunderstood because few experts (major COSS founders, investors, etc.) agree on implementation approaches and tradeoffs. This is disappointing.
Polarizing because pure OSS maximalists (mostly consisting of staunchly “pro-Red-Hat-business-model” types) quickly shun OC and go as far as synonymizing it with “fauxpensource”. This is, simply, glib.
Pure OSS service / SLA subscription-based software companies like Hortonworks and WSO2 commonly differentiate their offerings by shunning open core as “fake” open source and limiting/tarnished. These companies focus on promoting the fact that their offerings are “Certified Organic, Purebred, Grass Fed 100% Open Source!”.
Leaving all of these silly misunderstandings and polarizations aside, I re-introduced the COSSI in a previous post: an actively maintained Google Sheet of top-quartile commercial OSS businesses. One major conclusion to draw from COSSI’s data is that** open core is the dominant business model used by the most successful COSS companies.**
Note that I’m not saying that pure-OSS business models (training, support, services) are bad or can’t work. On the contrary, there are a few successful examples… but just a few (WSO2, Hortonworks, Red Hat), not many.
I believe $110B+ of value has been “captured” by OC-based companies (50+ examples, 30+ in COSSI) vs. maybe at most ~$30B (by really one single company: Red Hat) using pure-OSS models (support/training/services only).
In a future post, I’ll broadly compare and contrast different kinds of COSS business models (services, training, fully closed products, hardware, SaaS, and all the combos thereof), but here we’ll focus on open core.
What is open core?
Wikipedia’s current (likely to change) definition of open core is very lacking:
Open core is a business model for the monetization of commercially produced open-source software…the open-core model primarily involves offering a “core” or feature-limited version of a software product as free and open-source software, while offering “commercial” versions or add-ons as proprietary software.
While this definition covers some fundamental aspects (open core is fundamentally a business model for monetizing OSS), it conflates, omits and under-defines much:
- Open core applies just as well to commercially-produced OSS (Mule ESB at MuleSoft, for e.g.) as it does to industry-produced OSS (Apache Kafka at LinkedIn, for e.g.) as it does to academia-produced OSS (Apache Mesos at UC Berkeley, for e.g.). Wikipedia’s definition doesn’t cover that detail/nuance. In a future post, I’ll go into the implications of these different origins.
- The “core” is never a product, it is always a project — there are huge differences. OC products are commercially licensed (protecting / limiting access to IP; future posts will elaborate on this) and sold, whereas OSS projects are purely open sourced (also licensed, but all use OSS licenses) and maintained in the open (ideally).
- Distinguishing “commercial versions” with “add-ons” is critical: they also differ greatly. The former might mean a fork or the fork gradient thereof (forks can sometimes just carry patches, or major new code paths that dramatically diverge/extend the upstream core). The latter (“add-ons”) might mean that the OSS core is untouched but commercial extensions or add-on plugins are provided to “slot in” anywhere the OSS core runs without modification. One way to look at an example of commercial versions is the “packaging/distribution” approach (Cloudera’s distro for Hadoop, for e.g.). One way to look at an example of add-ons approach is the “plug-ins” approach (Hashicorp’s enterprise versions of Terraform and their other projects, for e.g.).
- Open core as a business model is not binary — it is implemented in many ways across what I like to think of as a* four-level representative spectrum*: skinny, thin, lean, thick.
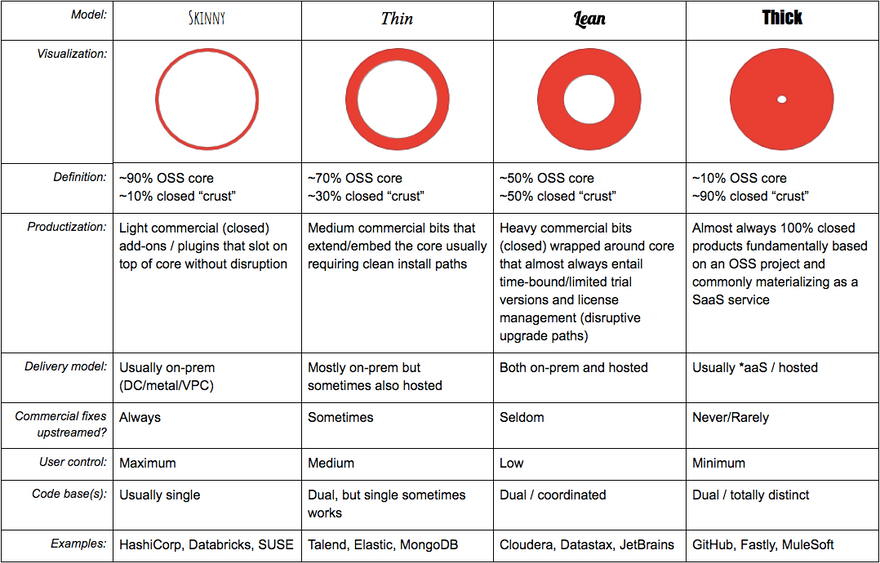
How is open core implemented?
Let’s dig into some of the details of the four proposed ways OC can be implemented. Note that this is a dramatic simplification and there are really 10s or even 100s of ways OC can be implemented. I have seriously oversimplified here the sake of boiling things down to the essentials.
Definition: The most fundamental aspect of OC lies in the question of “How much stays open vs. How much stays closed?”. I propose four roughly static snapshots of looking at this: skinny, thin, lean and fat. It can get far more nuanced and complex than this, though. In a future post, I will elaborate on what I call the “OC constant”, which is the continuous level of energy spent by OC companies (always across all functions: sales, marketing, engineering, product, delivery, etc.) to find the “OC equilibrium” which is the right balance of open/closed that yields product market fit and scalable revenue. Levers and knobs are constantly pushed, pulled and tuned in order to optimize and discover this equilibrium.
Productization: OC replaces (or extends) OSS projects with commercial products. As a consequence, the materialization and manifestation of the way those products come to life “productization” is a function of how OC is implemented along the spectrum I outline above (and all the ways in between skinny/thin/lean/fat).
Delivery model: This is really code for “How are the OC product bits shipped to a customer and/or consumed by said customer?”. OSS is used everywhere: on-prem in physical data centers, in the cloud, at the edge, etc. As a consequence, the vendors behind these OSS projects (the commercial OSS businesses) need to deliver their products into all of those environments reliably and with strong guarantees and consistency. Often, delivery models cover the gamut regardless of how OC is implemented, so this is a tricky one.
Commercial fixes upstreamed?: Typically, a given “successful” COSS company is the main committer (by full-time contributors employed by the company, influence over the roadmap, control over the codebase, etc.) behind the OSS project they are commercializing. The balance of what the upstream “pure OSS” non-customer user base sees and demands of the OSS project needs to align with the maturity path of enterprise customers and industry adoption (in production environments) of the OC product. This is another post entirely, so I’ll just leave it at that. In “thick” OC models, major changes are almost never pushed back upstream — minor ones are, of course, but because the OC product deviates so much/adds so much on top of the OSS project, there is little incentive, let alone demand to commit back.
**User control: **User control really means “How much is the pure OSS user community / individual able to influence and control the roadmap, direction, design and life of the OSS project that the OC product is based on?”. In “thick OC”, this is typically very hard since the project is almost entirely controlled by the company building product on top of it. Exceptions abound here, though — this is not always the case.
Code base(s): Often times, the OC product and the OSS project will be maintained in separate code bases. From what I’ve observed, it is best if there is tight integration and alignment with the engineering direction and knowledge across both code bases even if they are totally separate — which they usually are.
Examples: Some of these examples might be better classified in different models, so please don’t take this table as the final perspective here — referring back to the “OC equilibrium”, the one constant in OC is change. The model is always being fine-tuned and it is not uncommon for a company to start off “thin” and grow into “thick” over time… or even get “fat”. 😃
Finding the “Open Core Equilibrium”: When should open core be used?
If a given OSS project sits at a layer in the IT / software stack where there is historical conditioning to allocate budget or pay for production use — for e.g. where enterprise infra / platform / sw ops teams really “Feel” the pain of running said software in complex environments, this is usually a major factor in determining whether the project is a good candidate for the OC model.
Another big factor is how widely adopted the project is — not just in gross # of users, downloads, etc. but how “strategic” the project is becoming as a standard system in the industry and how quickly that happens.
One other huge factor, IMO, is whether the project meets the following criteria:
The OSS project must have a high propensity for a single vendor model vs multi-vendor model!
*What is a single vendor model? *Mule ESB is a single vendor OSS project (MuleSoft). Talend is a single vendor OSS project (Talend, Inc.). Apache Mesos is a single vendor OSS project (Mesosphere), Docker/Moby is a single vendor OSS project (Docker, Inc.).
What is a multi-vendor model? Hadoop is a project that has many vendors and this has made commercialization of the technology extremely competitive and difficult (competition eats profits and speeds commoditization, which is essentially bad). Kubernetes is another great example. As is OpenStack. As is Linux. As are other projects that do not have one single major company entity contributing most of the code/driving most of the influence.
There are exceptions to this all around! However, I will end by paraphrasing Andy Grove with “the last to commoditize thrive” which I believe means that in order to capture lots of value around a given OSS project, the rate of commoditization above the core must be controllable by a single entity to better adjust the value generation/capture dynamic over time.
In a future post I’ll explore details that go into determining how a given OSS project can have a high propensity for single vs multi-vendor commercialization dynamics.

Top comments (0)